AI & Machine Learning Technologies
Discover our suite of advanced AI technologies designed to transform your data into actionable insights and drive intelligent business decisions.
SaaS Architecture
We empower the pay-as-you-go model for ease of use
Clean UI/UX
AI products don't really have to be difficult to use
Seamless Integration
Our products integrate easily with other on-prem tools
Human Support
We ensure your success while using our products
Automate Factory AI Container Lifecycle with Docker SDK and Kubernetes Python Client
Discover how to automate the AI container lifecycle using Docker SDK and Kubernetes Python Client. Implement efficient workflows for scalable AI solutions.
Learn More
Automate Industrial AI Model Deployment Pipelines with Tekton and KServe
Discover how to automate industrial AI model deployment pipelines using Tekton and KServe. Learn best practices for seamless integration and enhanced efficiency.
Learn More
Automate Model Deployment Gates for Factory AI Releases with Argo Workflows and KServe
Discover how to automate model deployment gates for factory AI releases using Argo Workflows and KServe. Enhance deployment efficiency and reliability today!
Learn More
Automate Model Rollouts with ArgoCD and BentoML
Discover how to automate model rollouts with ArgoCD and BentoML. Learn deployment strategies and enhance your CI/CD pipelines for efficient AI integration.
Learn More
Autoscale Industrial AI Services Based on Inference Queue Depth with KServe and Prometheus Client
Discover how to autoscale industrial AI services using inference queue depth with KServe and Prometheus Client. Enhance efficiency and optimize resource use.
Learn More
Autoscale LLM Inference Endpoints with vLLM and KServe
Discover how to autoscale LLM inference endpoints using vLLM and KServe. Learn deployment strategies to optimize performance and resource utilization effectively.
Learn More
Build Cost-Efficient Multi-Cloud AI Training Pipelines with SkyPilot and KServe
Discover how to build cost-efficient multi-cloud AI training pipelines using SkyPilot and KServe. Master deployment strategies and optimize resources for scalable AI.
Learn More
Build Durable Industrial AI Task Orchestration with Retry Logic Using Temporal and FastAPI
Explore how to implement durable task orchestration for industrial AI using Temporal and FastAPI with retry logic. Enhance reliability and efficiency today!
Learn More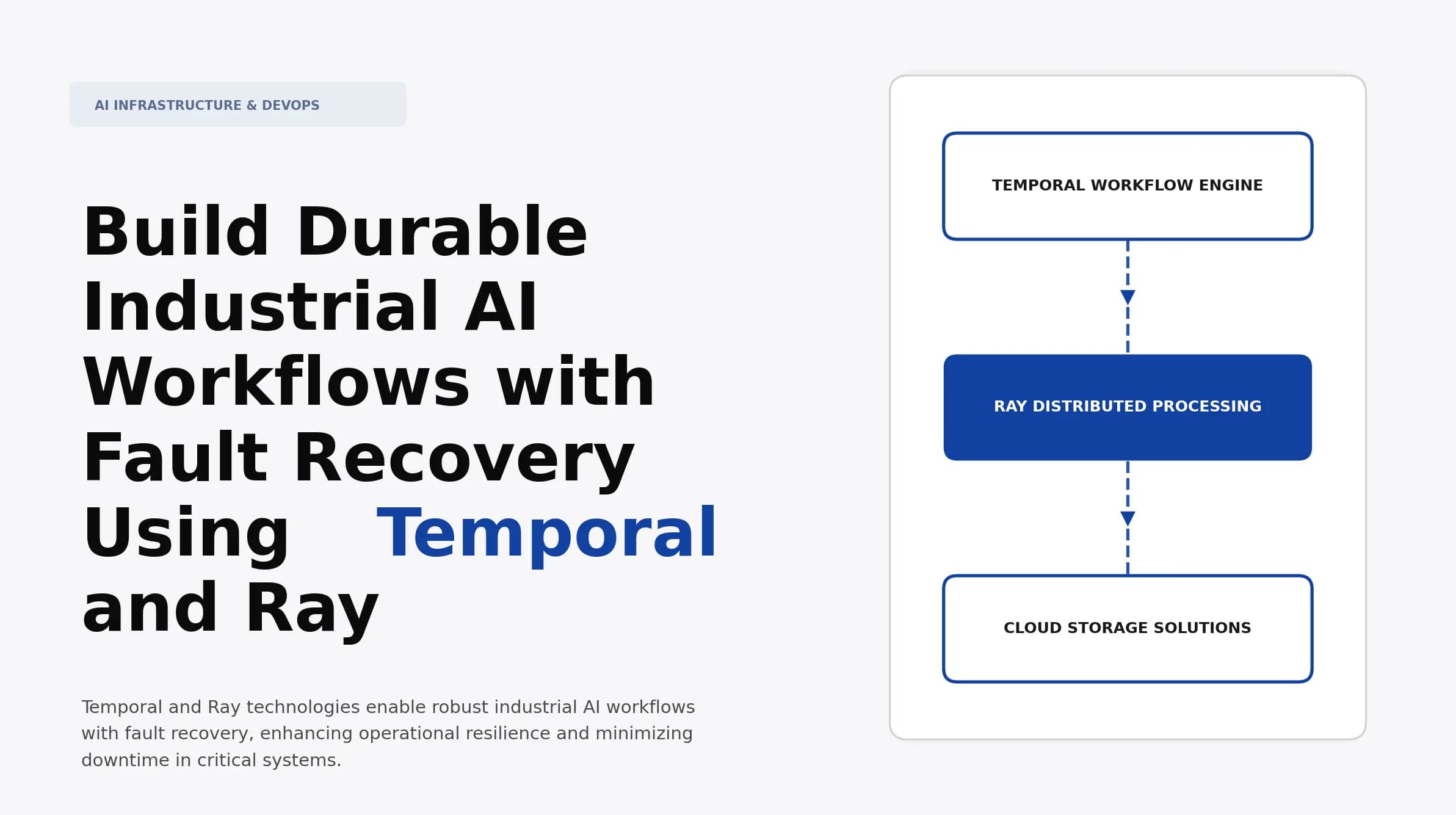
Build Durable Industrial AI Workflows with Fault Recovery Using Temporal and Ray
Discover how to build robust industrial AI workflows with fault recovery using Temporal and Ray. Learn best practices for resilience and performance.
Learn More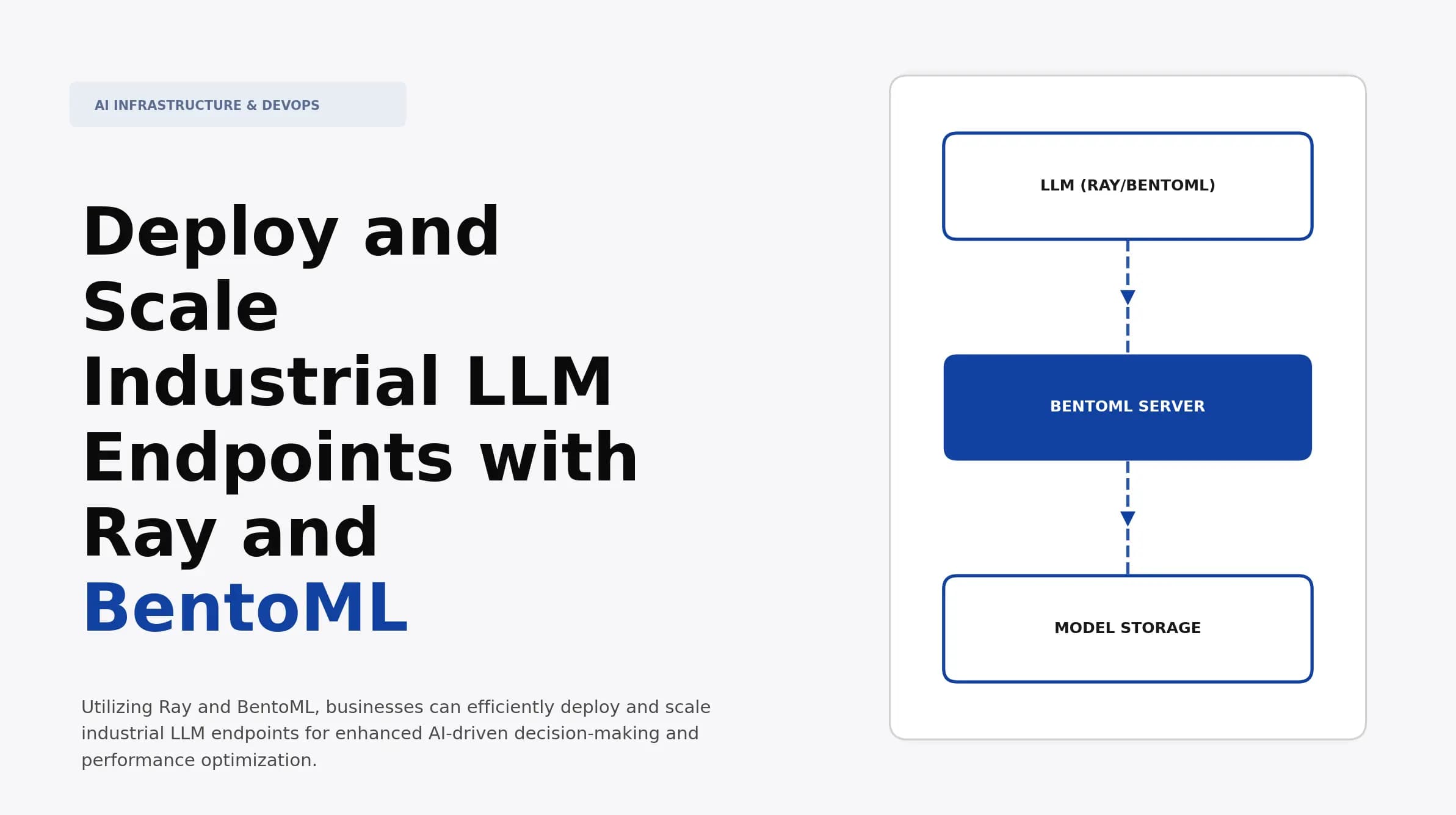
Deploy and Scale Industrial LLM Endpoints with Ray and BentoML
Discover how to deploy and scale Industrial LLM endpoints using Ray and BentoML. Learn effective strategies for enhancing AI application performance.
Learn More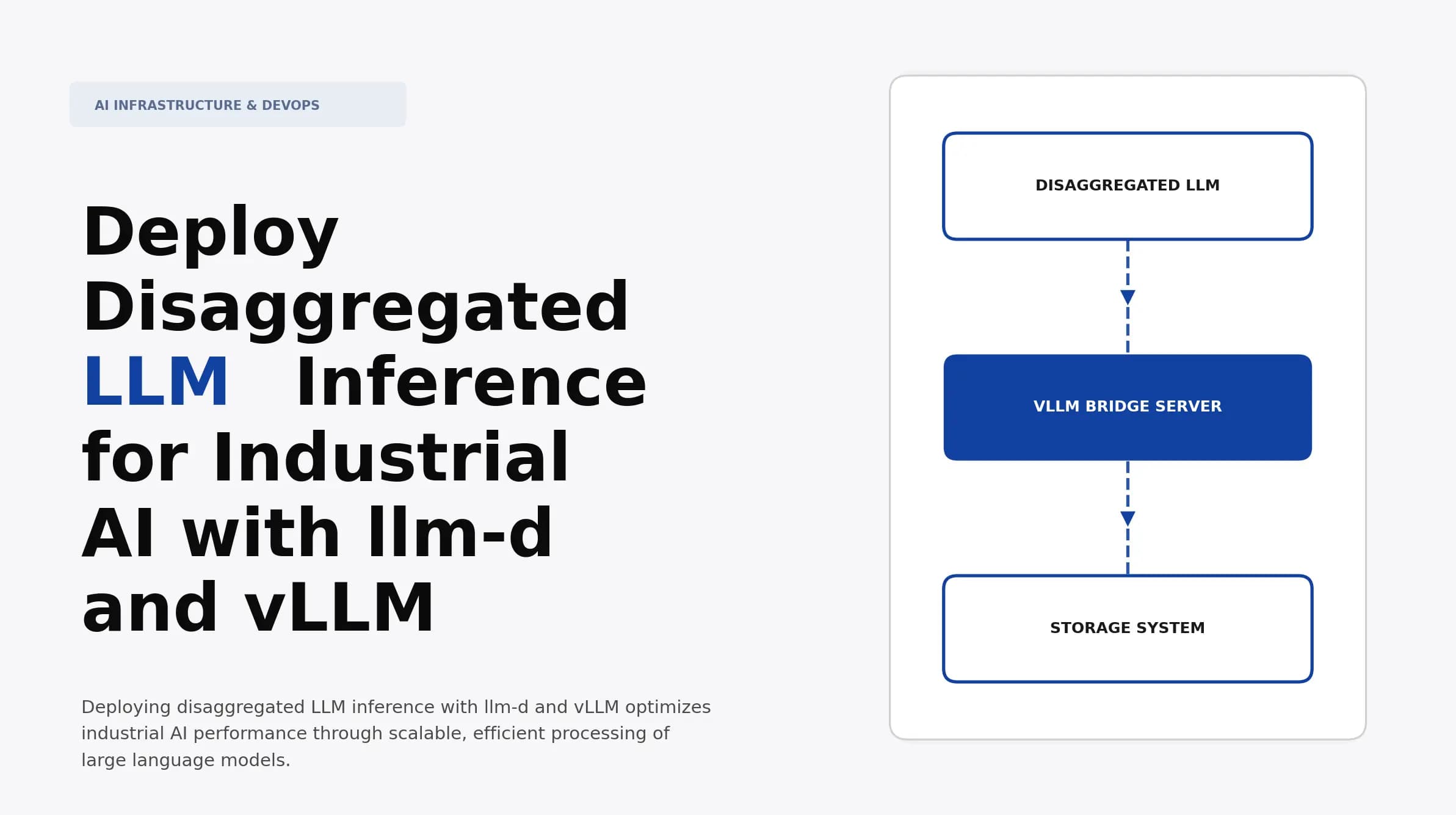
Deploy Disaggregated LLM Inference for Industrial AI with llm-d and vLLM
Discover how to implement disaggregated LLM inference for industrial AI using llm-d and vLLM. Learn about architecture, deployment strategies, and performance optimization.
Learn More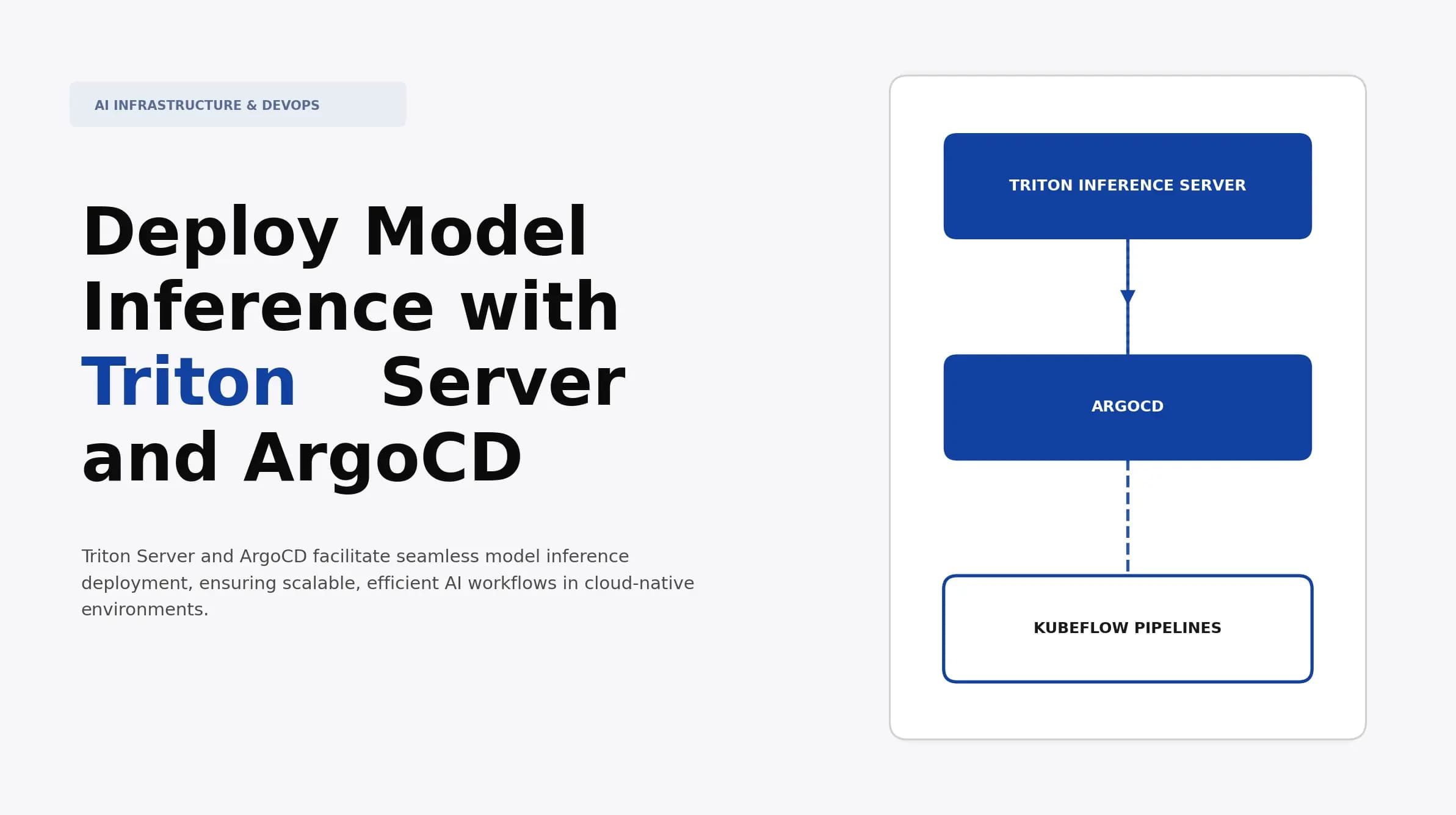
Deploy Model Inference with Triton Server and ArgoCD
Discover how to deploy model inference using Triton Server and ArgoCD. Implement scalable solutions to enhance AI performance and streamline operations.
Learn More
Deploy OpenAI-Compatible Industrial AI Services with KubeAI and vLLM
Discover how to deploy OpenAI-compatible industrial AI services using KubeAI and vLLM. Learn implementation strategies and optimize your AI infrastructure effectively.
Learn More
Deploy Rolling Model Updates for Industrial AI with Docker SDK and ArgoCD
Discover how to implement rolling model updates for Industrial AI using Docker SDK and ArgoCD. Enhance deployment efficiency and scalability for AI solutions.
Learn More
Deploy Versioned Industrial ML Models as Microservices with Flyte and KServe
Discover how to deploy versioned industrial ML models as microservices using Flyte and KServe. Master integration techniques for scalable AI solutions.
Learn More
Distribute Model Training Across Clouds with Ray and SkyPilot
Discover how to distribute model training across clouds using Ray and SkyPilot. Learn best practices for scaling AI workloads and optimizing performance.
Learn More
Implement AI-Driven Infrastructure Observability with Prometheus Client and KServe
Discover how to implement AI-driven infrastructure observability using Prometheus Client and KServe. Master monitoring strategies for enhanced performance and reliability.
Learn More
Implement Canary Model Deployments for Industrial AI with Seldon Core and ArgoCD
Discover how to implement canary model deployments for industrial AI using Seldon Core and ArgoCD. Enhance reliability and optimize performance in your AI systems.
Learn More
Implement GitOps Industrial AI Model Rollouts with Flux CD and KServe
Master GitOps for Industrial AI model rollouts using Flux CD and KServe. Discover streamlined deployment strategies, automation benefits, and efficiency gains.
Learn More
Implement Zero-Cost-When-Idle Industrial AI Serving with KEDA and BentoML
Discover how to implement zero-cost-when-idle industrial AI serving with KEDA and BentoML. Learn strategies for cost efficiency and scalable AI solutions.
Learn More
Implement Zero-Downtime Model Swaps for Industrial AI with Seldon Core and vLLM
Discover how to implement zero-downtime model swaps for industrial AI using Seldon Core and vLLM. Achieve seamless updates and enhanced reliability.
Learn More
Manage Industrial Model Fleets with Kubernetes Python Client and Seldon Core
Discover how to manage industrial model fleets using the Kubernetes Python client and Seldon Core for efficient AI deployment and optimization.
Learn More
Monitor AI Model Health with Prometheus Client and BentoML
Explore how to effectively monitor AI model health using Prometheus Client and BentoML. Learn best practices for maintaining optimal AI performance.
Learn More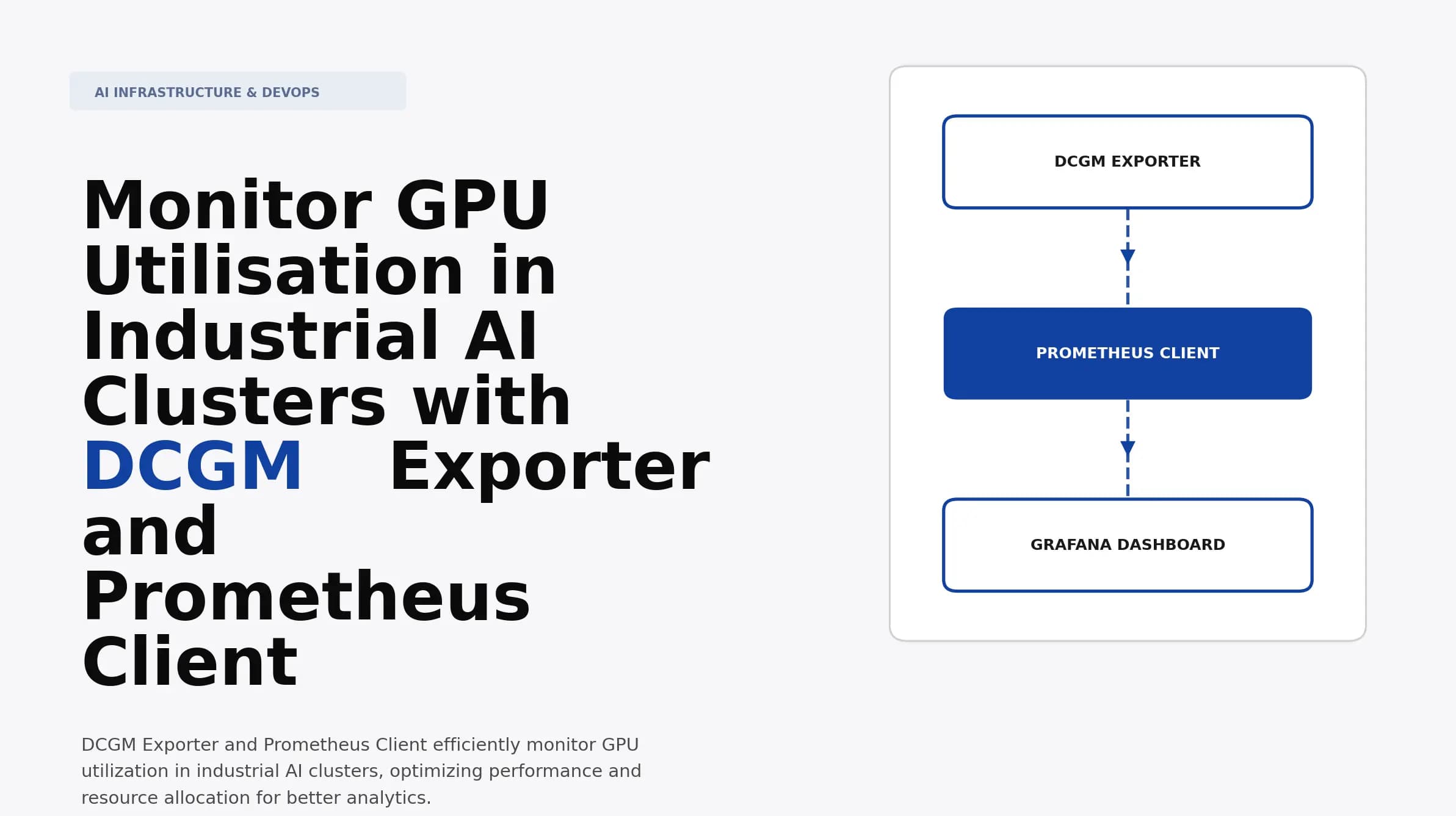
Monitor GPU Utilisation in Industrial AI Clusters with DCGM Exporter and Prometheus Client
Discover how to monitor GPU utilization in industrial AI clusters using DCGM Exporter and Prometheus Client. Optimize performance and ensure efficiency.
Learn More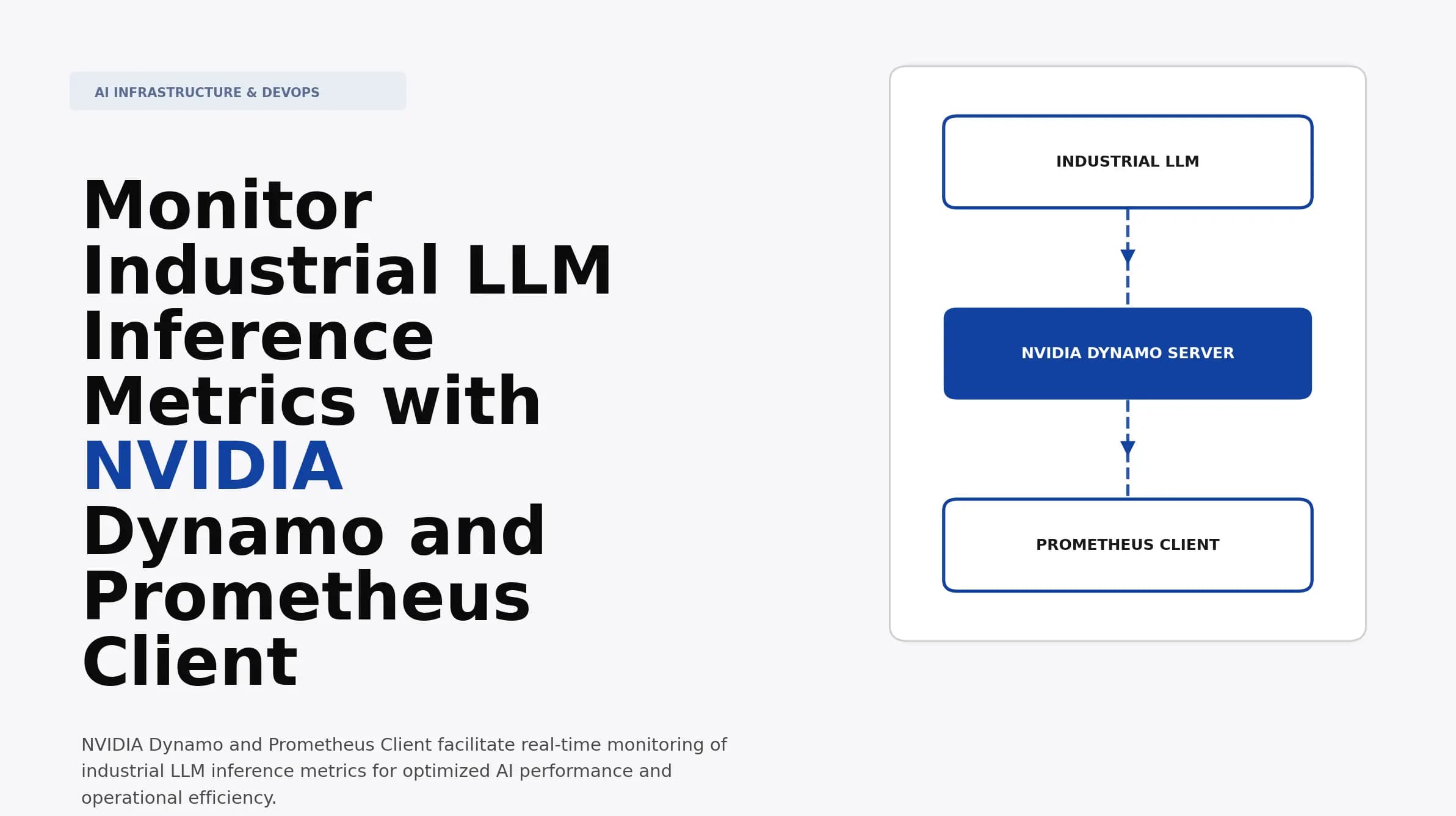
Monitor Industrial LLM Inference Metrics with NVIDIA Dynamo and Prometheus Client
Discover how to effectively monitor industrial LLM inference metrics using NVIDIA Dynamo and Prometheus Client. Implement insights to optimize AI performance.
Learn More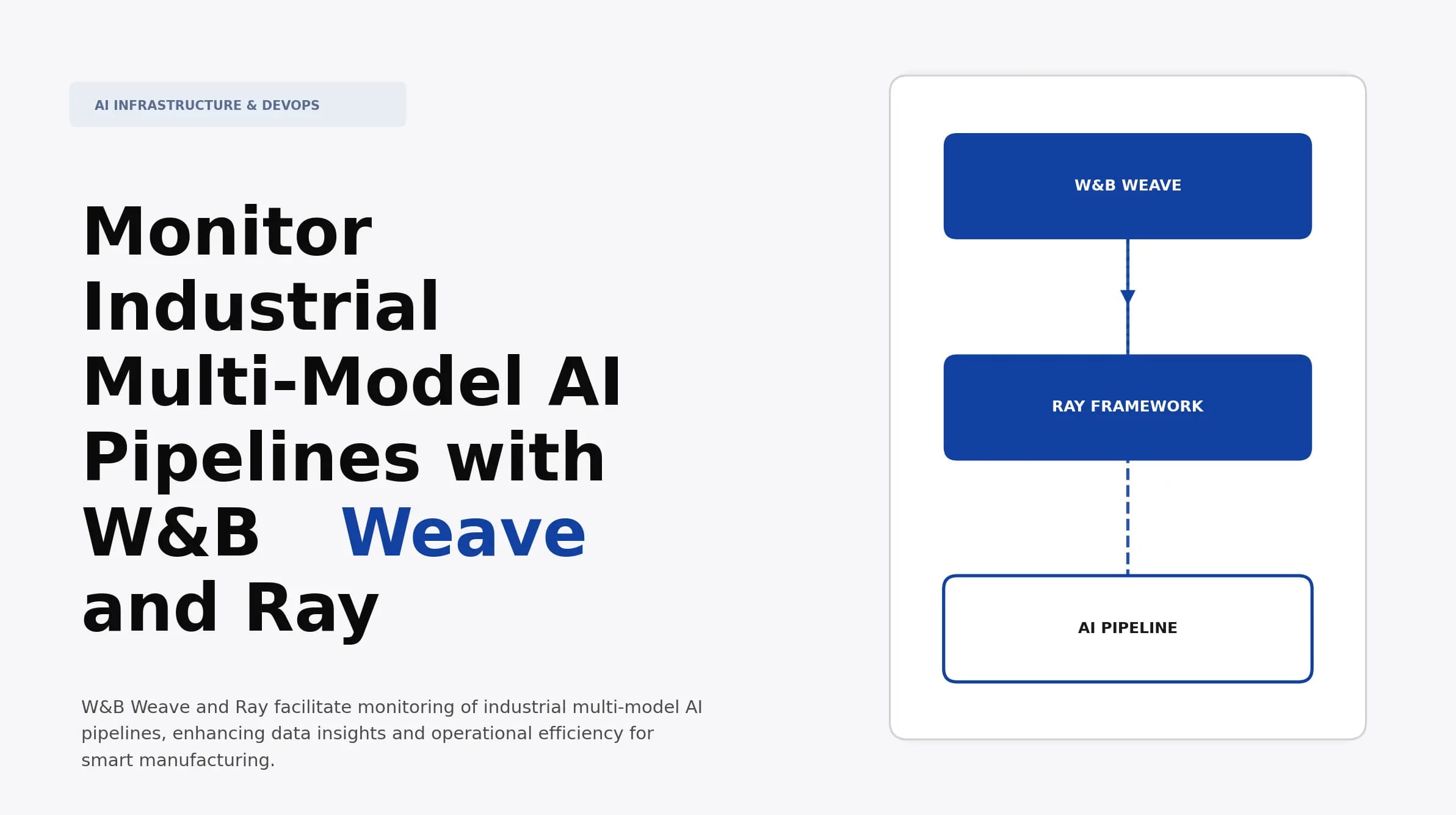
Monitor Industrial Multi-Model AI Pipelines with W&B Weave and Ray
Discover how to monitor industrial multi-model AI pipelines using W&B Weave and Ray. Learn best practices for optimization and real-time performance insights.
Learn More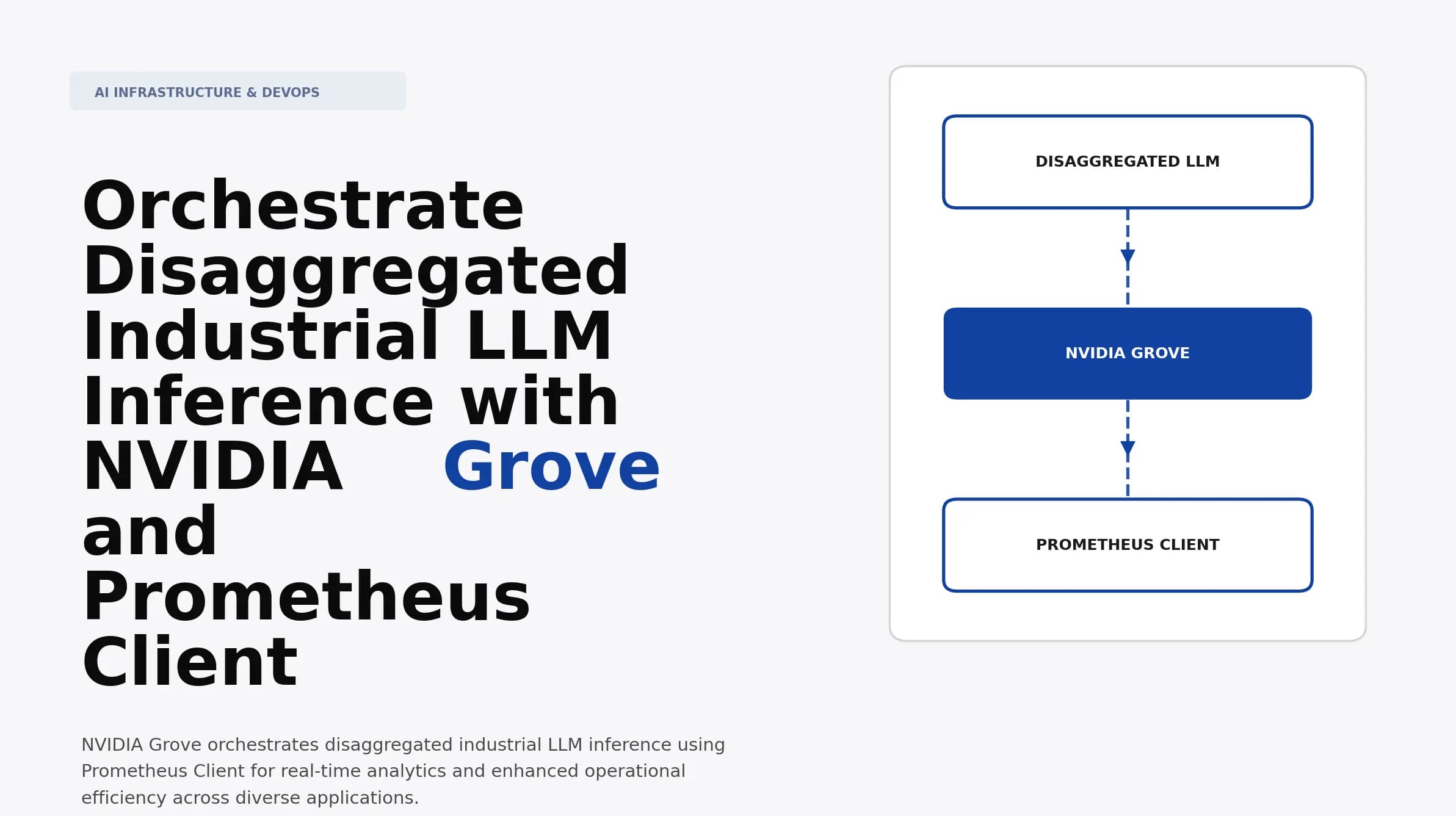
Orchestrate Disaggregated Industrial LLM Inference with NVIDIA Grove and Prometheus Client
Discover how to orchestrate disaggregated industrial LLM inference using NVIDIA Grove and Prometheus Client. Learn strategies for enhanced AI performance and scalability.
Learn More
Orchestrate Distributed AI Workloads with Ray and Kubernetes Python Client
Discover how to orchestrate distributed AI workloads using Ray and the Kubernetes Python Client. Enhance scalability and efficiency in your applications.
Learn More
Orchestrate Distributed Factory Model Training Across Cloud Providers with Flyte and Ray
Discover how to orchestrate distributed factory model training across cloud providers using Flyte and Ray. Maximize efficiency and scalability for AI workflows.
Learn More
Orchestrate GPU Prefill-Decode Inference for Factory AI with NVIDIA Dynamo and vLLM
Discover how to effectively orchestrate GPU Prefill-Decode inference for Factory AI using NVIDIA Dynamo and vLLM. Boost efficiency and performance today!
Learn More
Orchestrate Multi-Cloud AI Workloads with SkyPilot and Docker SDK
Discover how to orchestrate multi-cloud AI workloads using SkyPilot and Docker SDK. Learn deployment strategies and enhance efficiency for your projects.
Learn More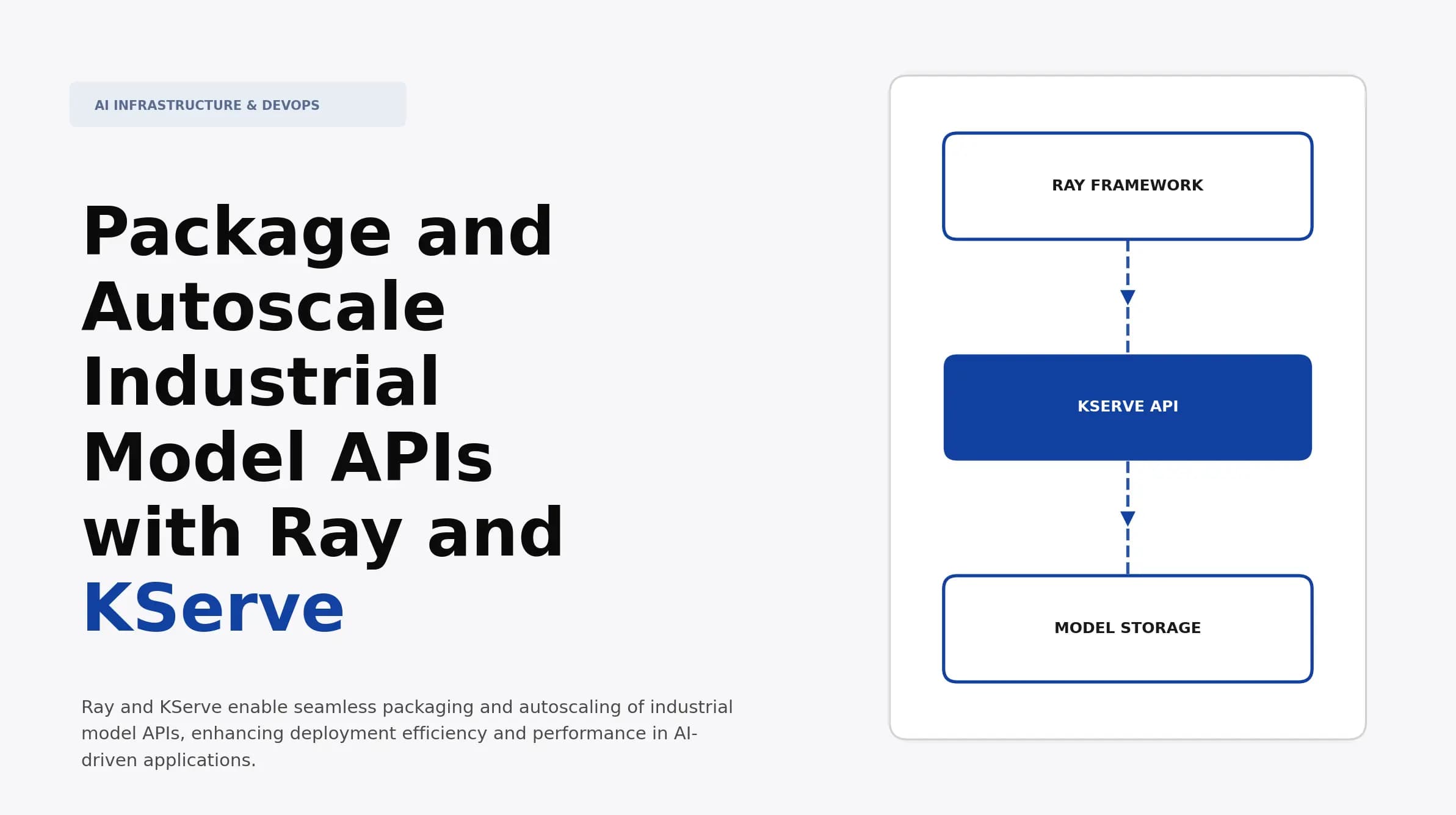
Package and Autoscale Industrial Model APIs with Ray and KServe
Discover how to package and autoscale industrial model APIs with Ray and KServe. Learn deployment strategies and optimize performance for enterprise applications.
Learn More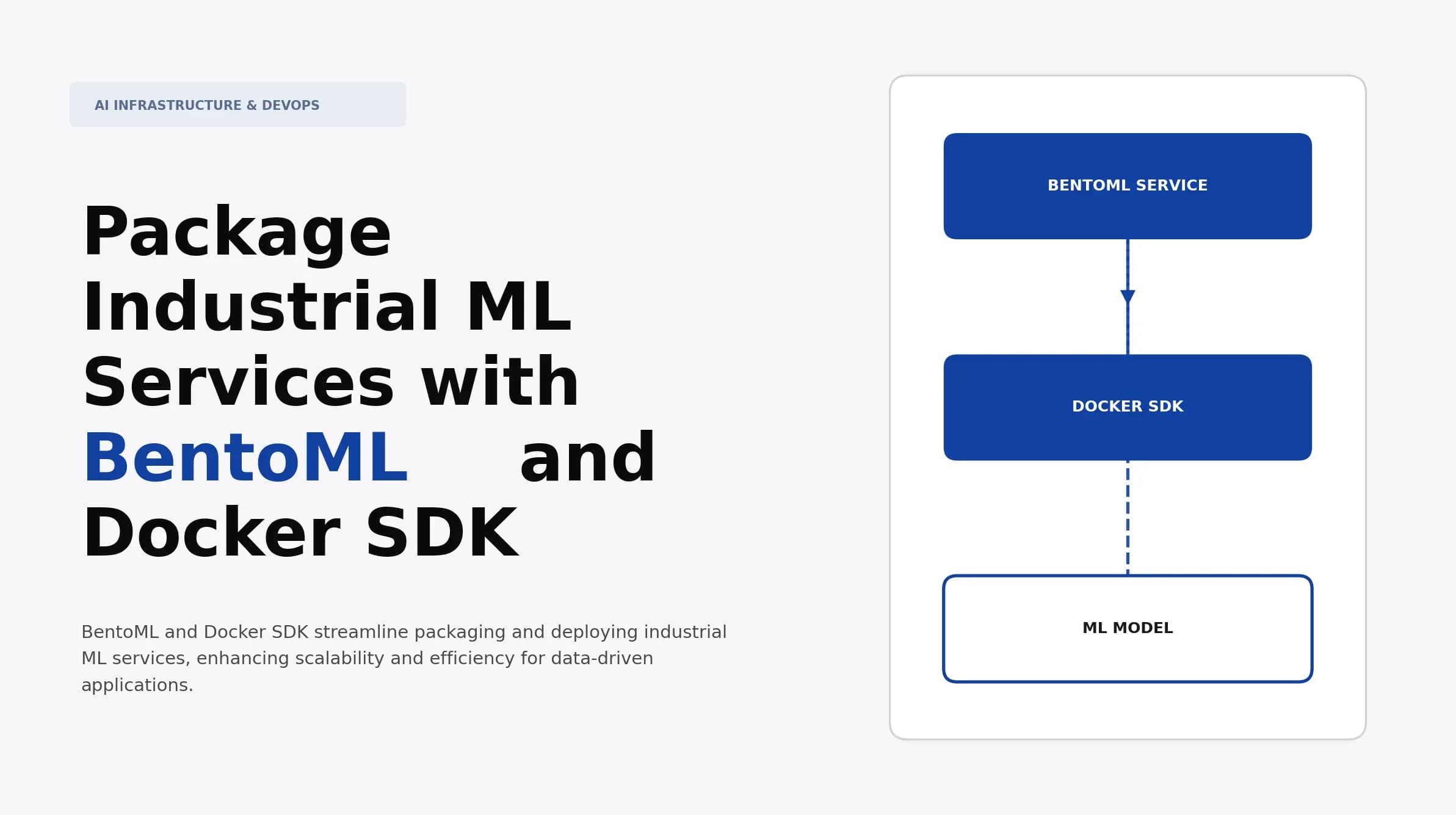
Package Industrial ML Services with BentoML and Docker SDK
Discover how to package industrial ML services using BentoML and Docker SDK. Learn deployment strategies, optimization techniques, and enhance scalability for AI.
Learn More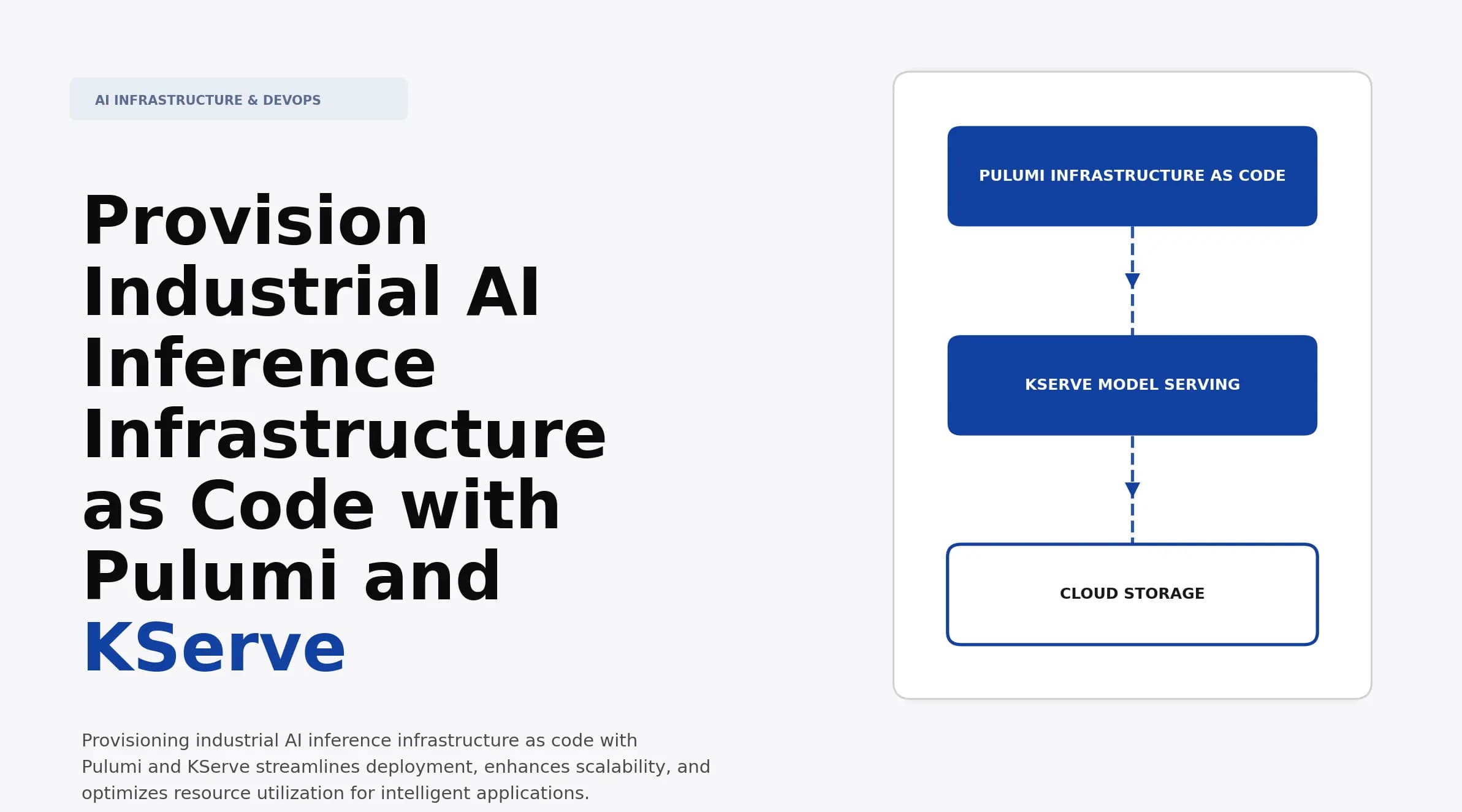
Provision Industrial AI Inference Infrastructure as Code with Pulumi and KServe
Discover how to provision industrial AI inference infrastructure as code with Pulumi and KServe. Learn deployment techniques to enhance AI application performance.
Learn More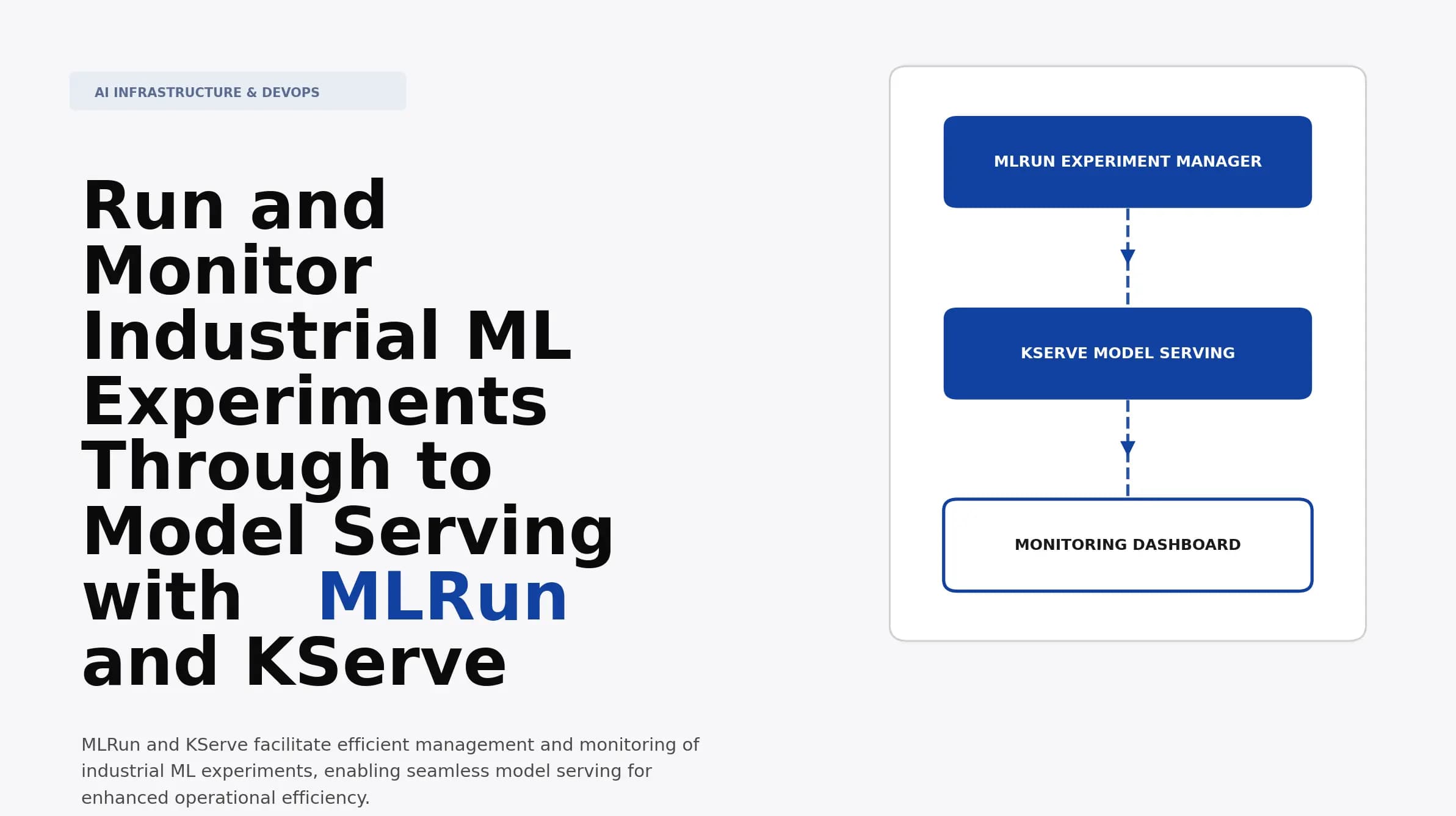
Run and Monitor Industrial ML Experiments Through to Model Serving with MLRun and KServe
Discover how to efficiently run and monitor industrial ML experiments with MLRun and KServe. Learn to streamline model serving for impactful AI outcomes.
Learn More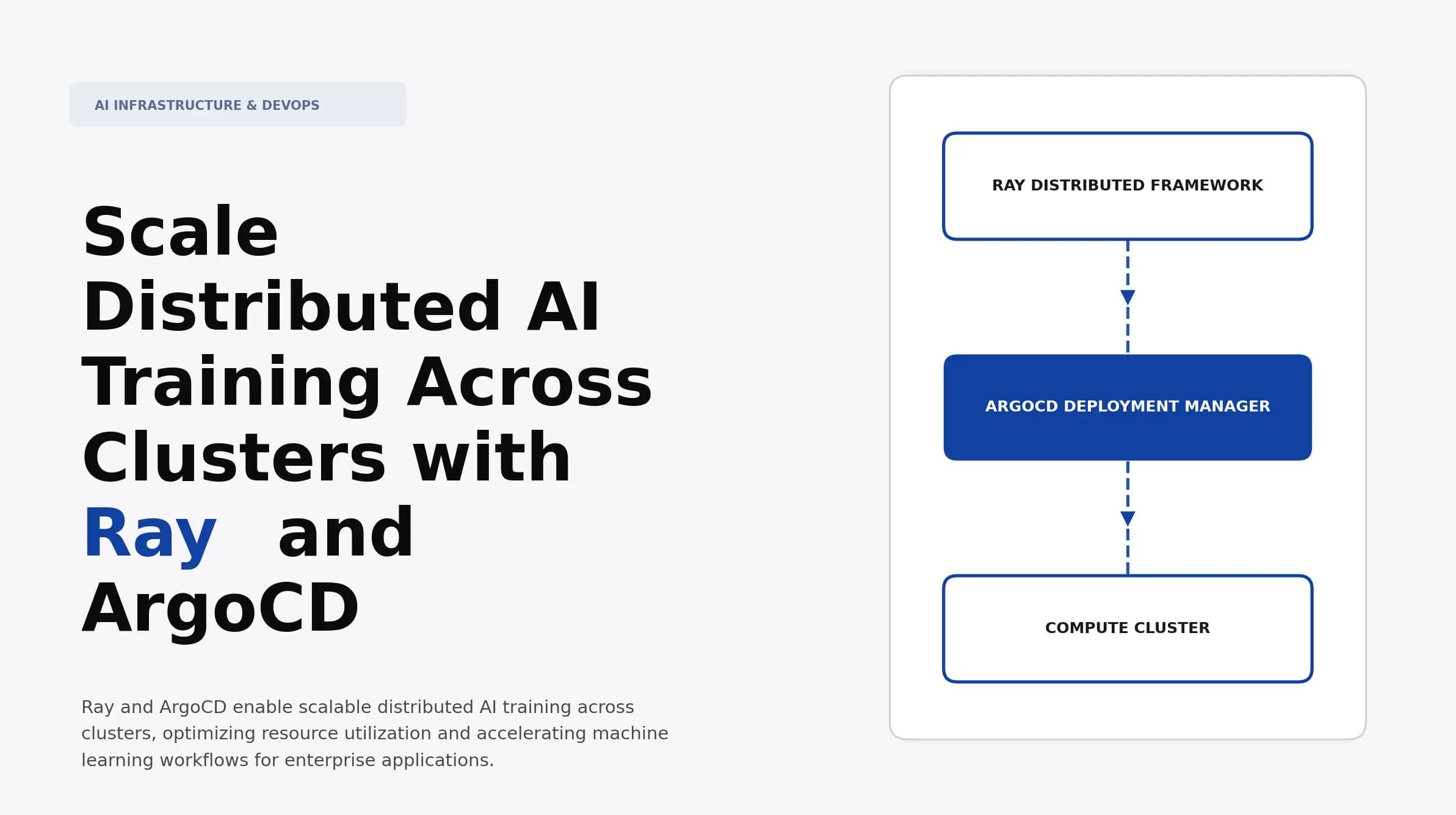
Scale Distributed AI Training Across Clusters with Ray and ArgoCD
Discover how to scale distributed AI training across clusters using Ray and ArgoCD. Learn best practices for efficiency and performance in your AI projects.
Learn More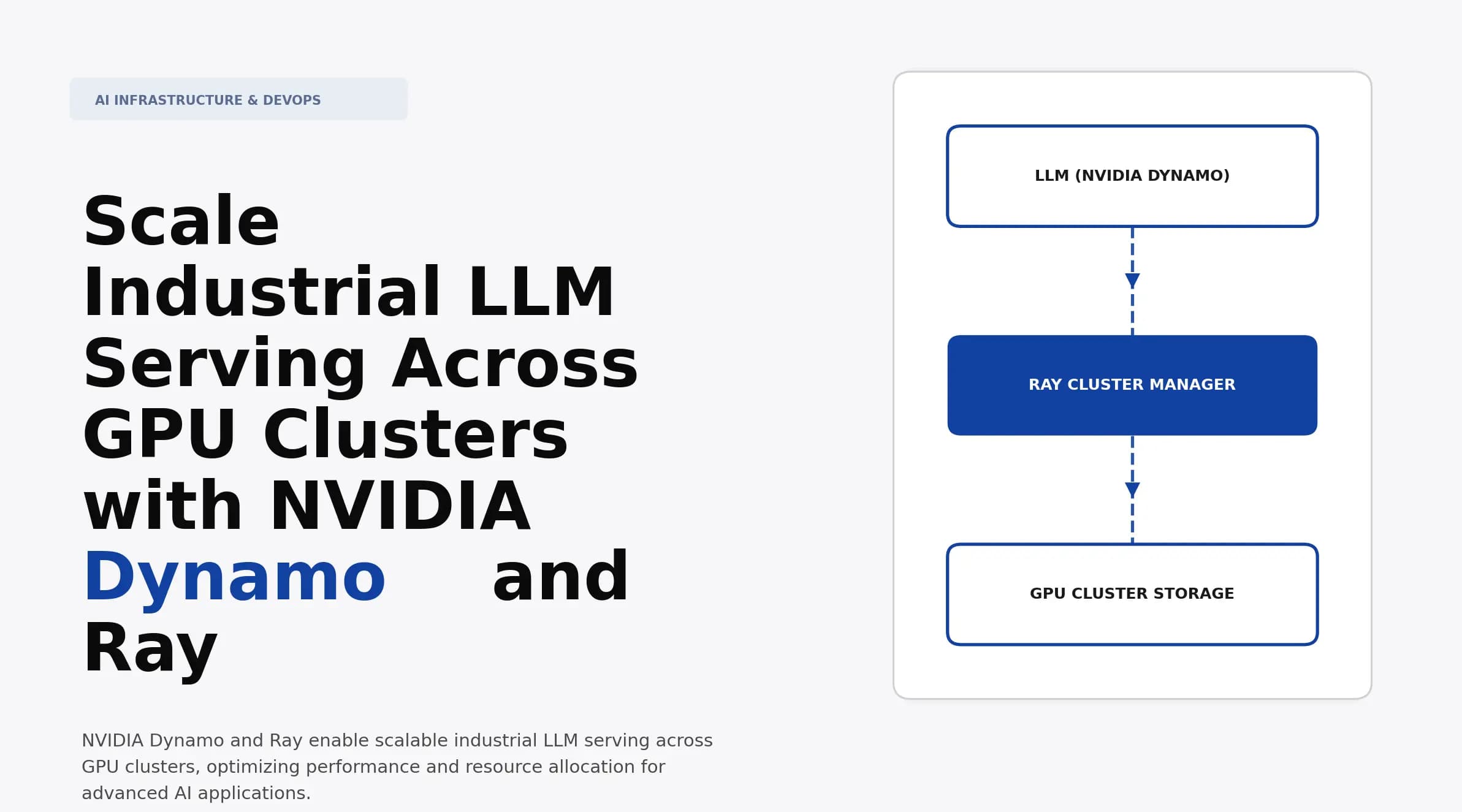
Scale Industrial LLM Serving Across GPU Clusters with NVIDIA Dynamo and Ray
Discover how to scale industrial LLM serving across GPU clusters using NVIDIA Dynamo and Ray. Implement strategies for efficient processing and deployment.
Learn More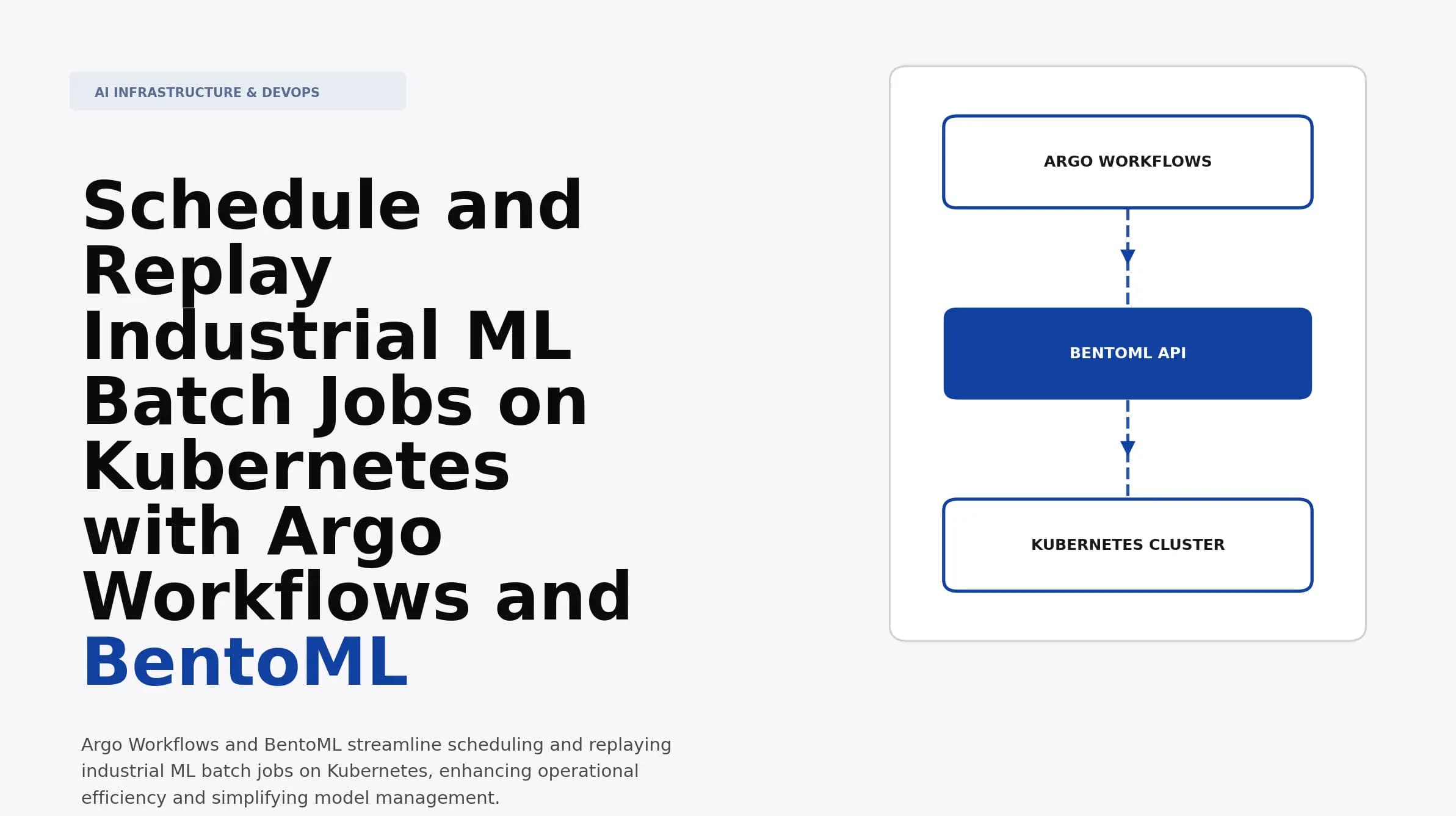
Schedule and Replay Industrial ML Batch Jobs on Kubernetes with Argo Workflows and BentoML
Master the art of scheduling and replaying industrial ML batch jobs using Argo Workflows and BentoML on Kubernetes. Optimize your workflows for better performance.
Learn More
Schedule Distributed Industrial AI Training on Kubernetes with Volcano and Ray
Discover how to schedule distributed AI training on Kubernetes using Volcano and Ray. Learn techniques to optimize resource allocation and enhance performance.
Learn More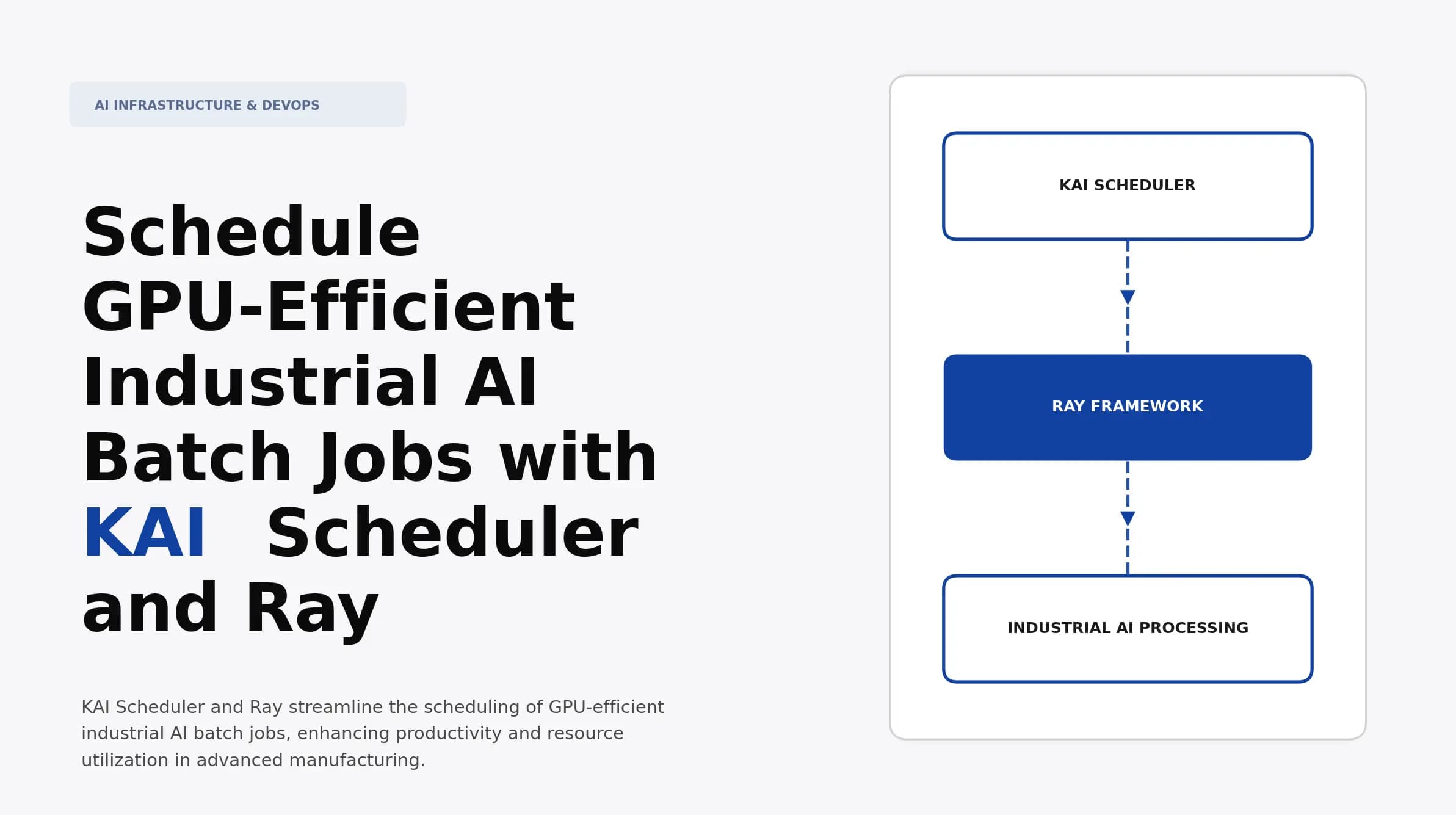
Schedule GPU-Efficient Industrial AI Batch Jobs with KAI Scheduler and Ray
Explore how to effectively schedule GPU-efficient industrial AI batch jobs using KAI Scheduler and Ray. Master performance optimization for your applications.
Learn More
Serve and Store Industrial AI Model Artifacts from On-Premises Object Storage with MinIO and BentoML
Discover how to efficiently serve and store industrial AI model artifacts using MinIO and BentoML with on-premises object storage solutions for optimal performance.
Learn More
Serve Production Models at Scale with Seldon Core and Prometheus Client
Discover how to serve production models at scale using Seldon Core and Prometheus Client. Learn best practices for deployment and monitoring in real-time environments.
Learn More
Store and Version Industrial AI Model Artifacts at Scale with MinIO and Ray
Master the storage and versioning of industrial AI model artifacts with MinIO and Ray. Discover best practices and strategies for seamless scalability and efficiency.
Learn More
Stream Inference Traces from Production Industrial Models with LangFuse and KServe
Learn how to effectively stream inference traces from industrial models using LangFuse and KServe. Discover best practices for real-time data insights and optimization.
Learn More
Trace and Debug Industrial AI Pipelines with OpenTelemetry and BentoML
Explore how to trace and debug industrial AI pipelines using OpenTelemetry and BentoML. Master best practices for enhanced observability and performance.
Learn More
Trace and Monitor Industrial LLM Inference with OpenTelemetry and KServe
Discover how to trace and monitor industrial LLM inference using OpenTelemetry and KServe. Learn to optimize performance and ensure reliability in AI operations.
Learn More
Trace Industrial AI Inference Latency with LangFuse and vLLM
Discover how to trace industrial AI inference latency using LangFuse and vLLM. Learn to optimize performance for real-time AI applications and enhance efficiency.
Learn More
Trace Inference Pipeline Latency with vLLM and OpenTelemetry
Discover how to trace inference pipeline latency using vLLM and OpenTelemetry. Master techniques to optimize performance and enhance AI application efficiency.
Learn More
Trace LLM Inference Pipelines for Factory AI with Langfuse and BentoML
Explore tracing LLM inference pipelines for Factory AI using Langfuse and BentoML. Learn best practices for optimizing AI workflows and enhancing performance.
Learn More
Track and Optimise Industrial AI Workload Costs with OpenCost and Kubernetes Python Client
Discover how to track and optimise industrial AI workload costs using OpenCost and Kubernetes Python Client. Learn cost management strategies to enhance efficiency.
Learn MoreReady to transform your business?
Unlock the power of AI-driven decision making
See how our technologies can revolutionize your data strategy and drive measurable business growth.
Schedule A Demo